联邦学习初见(二)
参考实现:https://github.com/shaoxiongji/federated-learning
首先给出FedAVG的目录 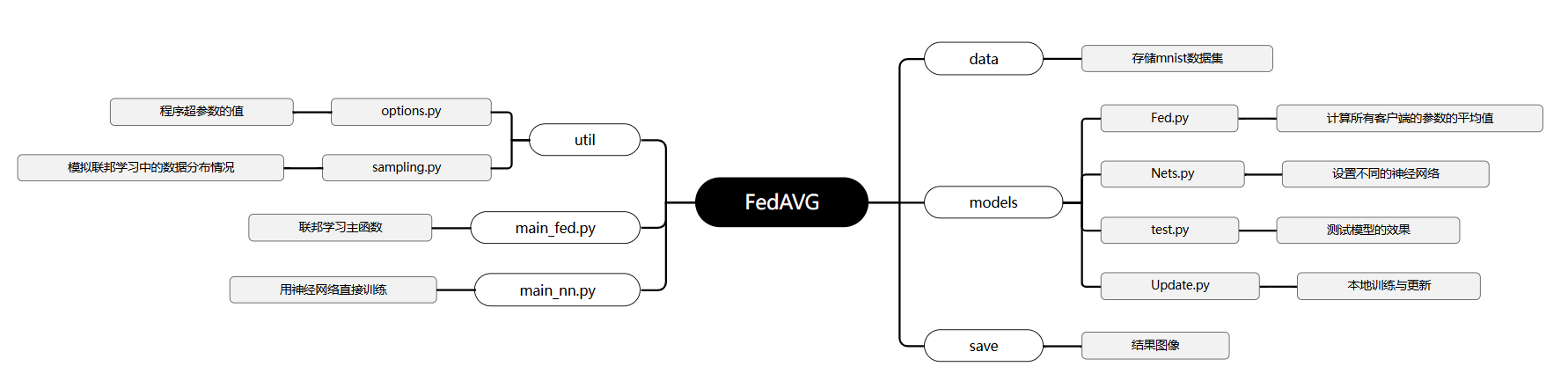 接着下面逐步解析其中的作用
接着下面逐步解析其中的作用
data
在此同样使用MNIST数据集
MNIST是一个大型手写数字数据库,常用于训练各种图像处理系统。它包含60,000个训练样本和10,000个测试样本,每个样本是一个28x28像素的灰度图像,表示从0到9的手写数字。MNIST数据集是机器学习和计算机视觉领域的经典数据集,常用于图像分类和模式识别任务。
models
Fed.py
1 | def FedAvg(w): |
首先是非常好理解的一个函数代码,就是对于每一个参数,计算所有客户端的参数的平均值,不过格式上可能需要理解,如下样例所示: 1
2
3
4
5
6w1 = {'layer1': torch.tensor([1.0, 2.0]), 'layer2': torch.tensor([3.0, 4.0])}
w2 = {'layer1': torch.tensor([2.0, 3.0]), 'layer2': torch.tensor([4.0, 5.0])}
w3 = {'layer1': torch.tensor([3.0, 4.0]), 'layer2': torch.tensor([5.0, 6.0])}
w = [w1, w2, w3]
w_avg = FedAvg(w)
print(w_avg)1
2
3
4{
'layer1': tensor([2.0, 3.0]),
'layer2': tensor([4.0, 5.0])
}
Nets.py
在此给出了三个神经网络结构,MLP、CNNMnist 和 CNNCifar,不过本文仅仅分析Mnist,所以Cifar姑且不谈,以下是每个类的简要说明: 1. MLP (多层感知器): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class MLP(nn.Module):
def __init__(self, dim_in, dim_hidden, dim_out):
super(MLP, self).__init__()
self.layer_input = nn.Linear(dim_in, dim_hidden)
self.relu = nn.ReLU()
self.dropout = nn.Dropout()
self.layer_hidden = nn.Linear(dim_hidden, dim_out)
def forward(self, x):
x = x.view(-1, x.shape[1]*x.shape[-2]*x.shape[-1])
x = self.layer_input(x)
x = self.dropout(x)
x = self.relu(x)
x = self.layer_hidden(x)
return x
- CNNMnist (用于 MNIST 数据集的卷积神经网络): 结构可以概述为 | 层类型 | 输入维度 | 输出维度 | 激活函数 | | ------------------ | ----------------------- | ----------------------- | -------- | | 输入层 | (args.num_channels, H, W) | | | | 卷积层1 | (args.num_channels, H, W) | (10, H-4, W-4) | ReLU | | 最大池化层1 | (10, H-4, W-4) | (10, (H-4)/2, (W-4)/2) | | | 卷积层2 | (10, (H-4)/2, (W-4)/2) | (20, (H-8)/2, (W-8)/2) | ReLU | | Dropout 层 | (20, (H-8)/2, (W-8)/2) | (20, (H-8)/2, (W-8)/2) | | | 最大池化层2 | (20, (H-8)/2, (W-8)/2) | (20, (H-8)/4, (W-8)/4) | | | 全连接层1 | 320 | 50 | ReLU | | Dropout 层 | 50 | 50 | | | 全连接层2 | 50 | args.num_classes | | | 输出层 | args.num_classes | | | 其中,H 是输入图像的高度,W 是输入图像的宽度,args.num_channels 是输入图像的通道数(例如,对于RGB图像,args.num_channels 通常是3) ## test.py 顾名思义,评估模型在测试集上的表现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class CNNMnist(nn.Module):
def __init__(self, args):
super(CNNMnist, self).__init__()
self.conv1 = nn.Conv2d(args.num_channels, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, args.num_classes)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, x.shape[1]*x.shape[2]*x.shape[3])
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return x## Update.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def test_img(net_g, datatest, args):
net_g.eval() #评估模式
test_loss = 0
correct = 0
data_loader = DataLoader(datatest, batch_size=args.bs) #加载测试集
for idx, (data, target) in enumerate(data_loader):
if args.gpu != -1:
data, target = data.cuda(), target.cuda() #数据加载到GPU
log_probs = net_g(data) #前向传播
test_loss += F.cross_entropy(log_probs, target, reduction='sum').item() #计算并累加当前批次的交叉熵损失
y_pred = log_probs.data.max(1, keepdim=True)[1] #找到概率最大的类别
correct += y_pred.eq(target.data.view_as(y_pred)).long().cpu().sum() #计算正确率
test_loss /= len(data_loader.dataset)
accuracy = 100.00 * correct / len(data_loader.dataset)
if args.verbose:
print('\nTest set: Average loss: {:.4f} \nAccuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, correct, len(data_loader.dataset), accuracy))
return accuracy, test_loss可以根据索引划分数据集并创建相应的训练集和验证集1
2
3
4
5
6
7
8
9
10
11class DatasetSplit(Dataset):
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = list(idxs)
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
return image, label
1 | class LocalUpdate(object): |
这个 LocalUpdate 类的 train 方法是比较基本的训练神经网络模型方法。 1. 首先将网络设置为训练模式,然后创建一个基于随机梯度下降(SGD)的优化器,并设置学习率和动量。 2. 接着,函数开始进行多个训练周期(由self.args.local_ep指定)。 3. 在每个训练周期中,函数遍历训练数据集的每个批次,将图像和标签数据移动到指定的设备上,然后清空网络的梯度,通过网络前向传播得到对数概率,计算损失函数,执行反向传播以计算梯度,并通过优化器更新网络的权重。 4. 在每个批次的训练过程中,如果设置了详细输出,并且当前批次是10的倍数,则打印出当前的训练进度和损失值。 5. 最后,函数记录每个周期的平均损失,并返回最终训练好的网络的参数状态字典以及所有周期的平均损失。
util
options.py
超参数,姑且不表,help已经明示 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36def args_parser():
parser = argparse.ArgumentParser()
# federated arguments
parser.add_argument('--epochs', type=int, default=10, help="rounds of training")
parser.add_argument('--num_users', type=int, default=100, help="number of users: K")
parser.add_argument('--frac', type=float, default=0.1, help="the fraction of clients: C")
parser.add_argument('--local_ep', type=int, default=5, help="the number of local epochs: E")
parser.add_argument('--local_bs', type=int, default=10, help="local batch size: B")
parser.add_argument('--bs', type=int, default=128, help="test batch size")
parser.add_argument('--lr', type=float, default=0.01, help="learning rate")
parser.add_argument('--momentum', type=float, default=0.5, help="SGD momentum (default: 0.5)")
parser.add_argument('--split', type=str, default='user', help="train-test split type, user or sample")
# model arguments
parser.add_argument('--model', type=str, default='mlp', help='model name')
parser.add_argument('--kernel_num', type=int, default=9, help='number of each kind of kernel')
parser.add_argument('--kernel_sizes', type=str, default='3,4,5',
help='comma-separated kernel size to use for convolution')
parser.add_argument('--norm', type=str, default='batch_norm', help="batch_norm, layer_norm, or None")
parser.add_argument('--num_filters', type=int, default=32, help="number of filters for conv nets")
parser.add_argument('--max_pool', type=str, default='True',
help="Whether use max pooling rather than strided convolutions")
# other arguments
parser.add_argument('--dataset', type=str, default='mnist', help="name of dataset")
parser.add_argument('--iid', action='store_true', help='whether i.i.d or not')
parser.add_argument('--num_classes', type=int, default=10, help="number of classes")
parser.add_argument('--num_channels', type=int, default=3, help="number of channels of imges")
parser.add_argument('--gpu', type=int, default=0, help="GPU ID, -1 for CPU")
parser.add_argument('--stopping_rounds', type=int, default=10, help='rounds of early stopping')
parser.add_argument('--verbose', action='store_true', help='verbose print')
parser.add_argument('--seed', type=int, default=1, help='random seed (default: 1)')
parser.add_argument('--all_clients', action='store_true', help='aggregation over all clients')
args = parser.parse_args()
return args
sampling.py
主要是采样相关的函数, 1
2
3
4
5
6
7
8
9
10
11
12
13def mnist_iid(dataset, num_users):
"""
Sample I.I.D. client data from MNIST dataset
:param dataset:
:param num_users:
:return: dict of image index
"""
num_items = int(len(dataset)/num_users)
dict_users, all_idxs = {}, [i for i in range(len(dataset))]
for i in range(num_users):
dict_users[i] = set(np.random.choice(all_idxs, num_items, replace=False))
all_idxs = list(set(all_idxs) - dict_users[i])
return dict_users
1 | def mnist_noniid(dataset, num_users): |
用于从MNIST数据集中为每个用户采样非独立同分布(Non-I.I.D.)的数据,具体是将数据集按标签排序并分片,然后将每个用户的数据样本限制在某几个片段内,确保每个用户的数据样本是非独立同分布的。 # main_fed.py ## 解析参数 1
2args = args_parser()
args.device = torch.device('cuda:{}'.format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')1
2
3
4
5
6
7
8
9
10# 加载数据集并划分用户
if args.dataset == 'mnist':
trans_mnist = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
dataset_train = datasets.MNIST('../data/mnist/', train=True, download=True, transform=trans_mnist)
dataset_test = datasets.MNIST('../data/mnist/', train=False, download=True, transform=trans_mnist)
# 采样用户
if args.iid:
dict_users = mnist_iid(dataset_train, args.num_users)
else:
dict_users = mnist_noniid(dataset_train, args.num_users)1
2
3
4
5
6
7
8
9
10
11
12
13
14# 构建模型
if args.model == 'cnn' and args.dataset == 'cifar':
net_glob = CNNCifar(args=args).to(args.device)
elif args.model == 'cnn' and args.dataset == 'mnist':
net_glob = CNNMnist(args=args).to(args.device)
elif args.model == 'mlp':
len_in = 1
for x in img_size:
len_in *= x
net_glob = MLP(dim_in=len_in, dim_hidden=200, dim_out=args.num_classes).to(args.device)
else:
exit('Error: unrecognized model')
print(net_glob)
net_glob.train()1
w_glob = net_glob.state_dict()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32cv_loss, cv_acc = [], []
val_loss_pre, counter = 0, 0
net_best = None
best_loss = None
val_acc_list, net_list = [], []
if args.all_clients:
print("Aggregation over all clients")
w_locals = [w_glob for i in range(args.num_users)]
for iter in range(args.epochs):
loss_locals = []
if not args.all_clients:
w_locals = []
m = max(int(args.frac * args.num_users), 1)
idxs_users = np.random.choice(range(args.num_users), m, replace=False)
for idx in idxs_users:
local = LocalUpdate(args=args, dataset=dataset_train, idxs=dict_users[idx])
w, loss = local.train(net=copy.deepcopy(net_glob).to(args.device))
if args.all_clients:
w_locals[idx] = copy.deepcopy(w)
else:
w_locals.append(copy.deepcopy(w))
loss_locals.append(copy.deepcopy(loss))
# 更新全局权重
w_glob = FedAvg(w_locals)
# 复制权重到 net_glob
net_glob.load_state_dict(w_glob)
# 打印损失
loss_avg = sum(loss_locals) / len(loss_locals)
print('Round {:3d}, Average loss {:.3f}'.format(iter, loss_avg))
loss_train.append(loss_avg)
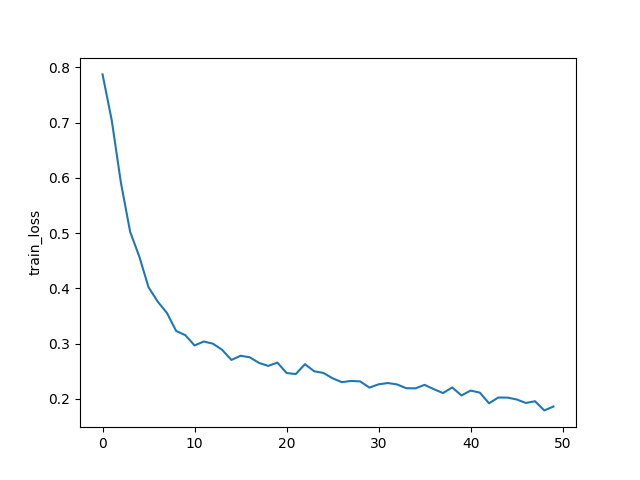
绘制损失曲线
1 | plt.figure() |
测试
1 | net_glob.eval() |
实验
实验环境
- PyTorch:
2.0.0 - Python:
3.8 (ubuntu20.04) - Cuda:
11.8 - GPU:
RTX 3090 (24GB) * 1
实验指令 1
python main_fed.py --dataset mnist --iid --num_channels 1 --model mlp --epochs 50 --gpu 0 --all_clients